More accurately predict risk in a changing auto insurance environment using driving behavior-based data.
Given today’s challenges and competition to accurately assess risk and loss propensity, how can you leverage driving behavior insights and a telematics-based scoring model to more effectively rate risk? These four critical factors are crucial to keep in mind when evaluating a scoring model:
Does the model leverage robust and credible telematics data?
Is the telematics model designed to complement other rating factors?
Are the telematics attributes―and overall score―reasonable and consistent?
Does the telematics model include coverage-specific performance insights and rating factors?
The raw ingredients for the model, the telematics data, must be credible in order to generate a strong performing model. There are four caveats for robust and credible data. First, data hygiene must be performed, whether it is smartphone, OBD-II or connected car data. This helps to remove suspicious, erroneous or invalid data points or questionable trips.
Second, to generate the most accurate score, the model should be derived from minimum data thresholds, such as number of days driving, total distance traveled, total trips, and days between first and last trips. A model that uses three or six months of data captured will be much stronger than one that only includes a few weeks of data.
Third, the modeling sample should be tied to at-fault claims and include as many vehicles as possible to garner a substantial number of claims in each modeling and performance bucket. You want to see hundreds or thousands of trips per record and as many records as possible for clear model segmentation.
Lastly, attributing telematics data to the right consumer household is essential. This means the telematics data should match the prospective or current insured. In the case of smartphone apps, the data captured should reflect only actual driving trips and not passenger trips such as those taken in a bus or taxi. In the case of connected vehicles, input should only include driving and claims data for the vehicle while it was owned by the same household. If only the VIN is used for matching, it may leave room for error in assigning data to the incorrect vehicle owner household. particularly when there is a change in vehicle ownership.
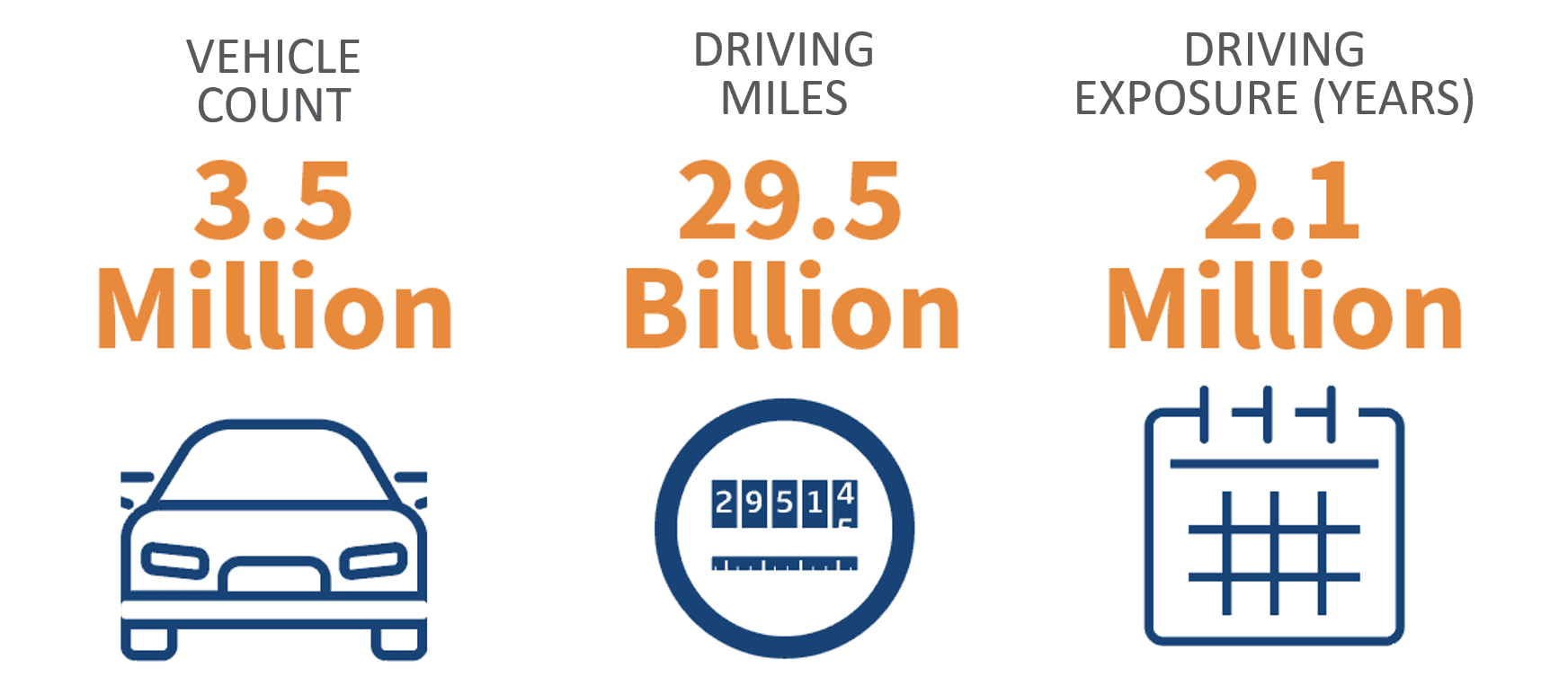
LexisNexis® Risk Solutions has developed a new, robust, telematics-based scoring model that incorporates a large volume of driving behavior and claims data, amounting to millions of vehicles, millions of car years of exposure, billions of trips and tens of billions of miles.
Figure 2. LexisNexis telematics scoring model incorporates a large volume of vehicles, driving miles and car years of exposure.
To help ensure its credibility, this new model uses data that has undergone multiple levels of enrichment, normalization, cleansing and filtering so that only valid events make it into the final model—avoiding event anomalies and outliers. We modeled with five to six months of data and validated performance on one, two, three, four and five months of data for the same pool of risks. We also applied our proprietary linking technology to ensure that all data for a vehicle had the same insured household ownership for the entire data capture through the target claims window.
For many carriers, standard rating factors are here to stay. Thus, a telematics model should be designed to be used among other standard variables. Furthermore, many traditional rating factors can provide quite different and complementary views to telematics. To allow insurers to evaluate prospects and existing customers at a more granular level, a telematics-based scoring model intended to be used in a rating plan should actually work with other factors in the rating plan.
Some of the attributes within the telematics model can be correlated with standard rating factors or base premiums. The objective should not be to maximize the performance of a standalone telematics model but to maximize the performance of the telematics model in conjunction with standard rating factors―which is likely how the model is used in insurance rating plans.
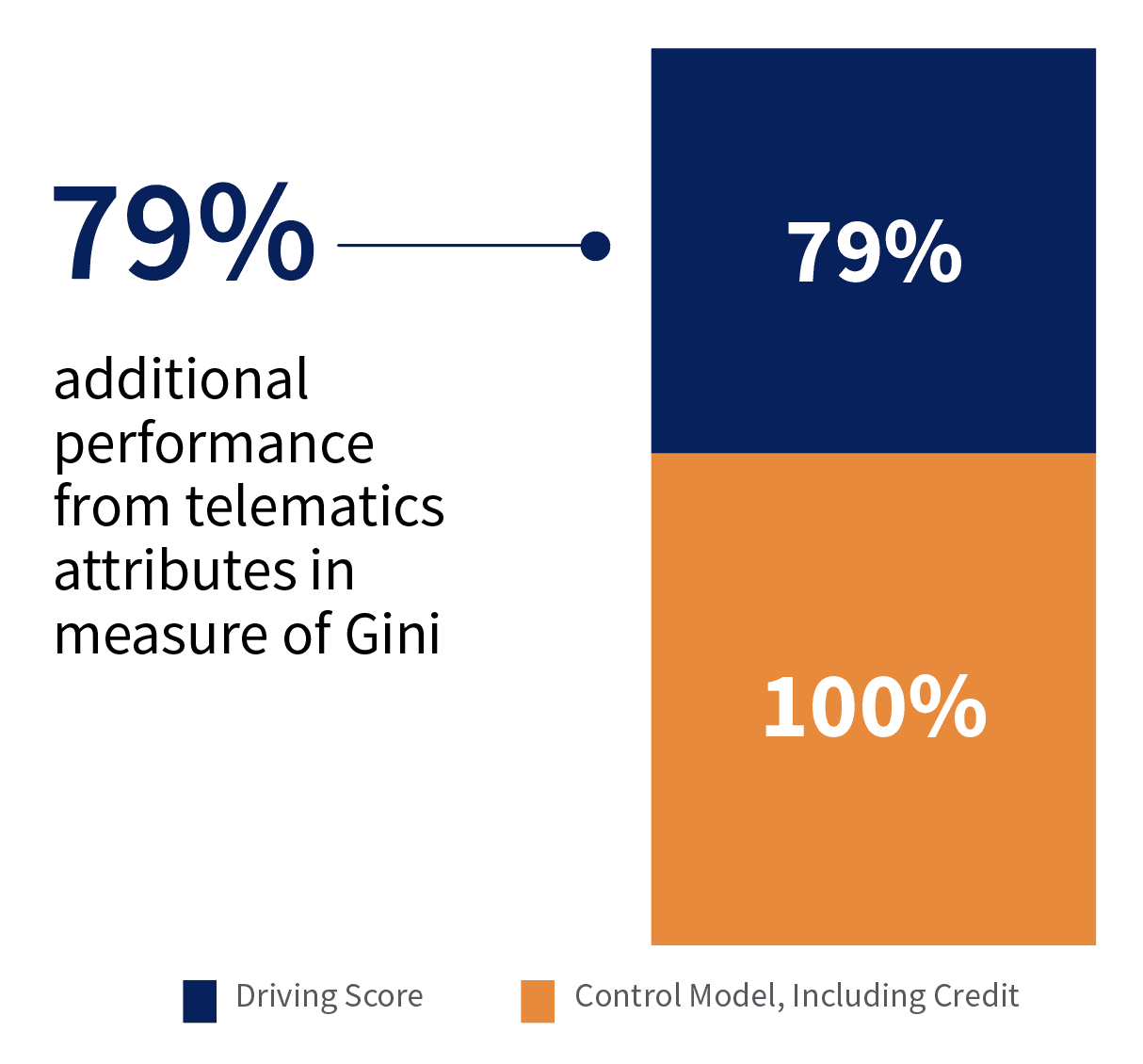
When we built our new telematics-based scoring model, we controlled for standard rating factors and focused on maximizing the performance of the combined model that accounts for both standard rating variables and telematics attributes. We observed 79% additional lift above standard rating factors to the predictability of driving risk, as seen in Figure 3. Lift can further increase as additional behavioral attributes are included. There is tremendous potential for future rating factors, such as advanced driver assistance systems (ADAS) sensors from connected vehicles, to provide even more segmentation.
Figure 3. There is improvement in lift when LexisNexis telematics data is used.
When considering attributes to include in a telematics model, a human hand is required. Otherwise, when relying solely on an automated process to pull attributes into the model, attributes that are not conceptually reasonable might enter the model. To ensure optimal performance, all the attributes used in the telematics model should have some human oversight to confirm they are reasonable, provable and justifiable.
For example, an attribute could appear correlated with claims and might add lift to a model. However, if the attribute only represents a fraction of the driver’s behaviors or some anomalous events, it should not be included. Each attribute—and the directional performance of each attribute—should make sense conceptually.
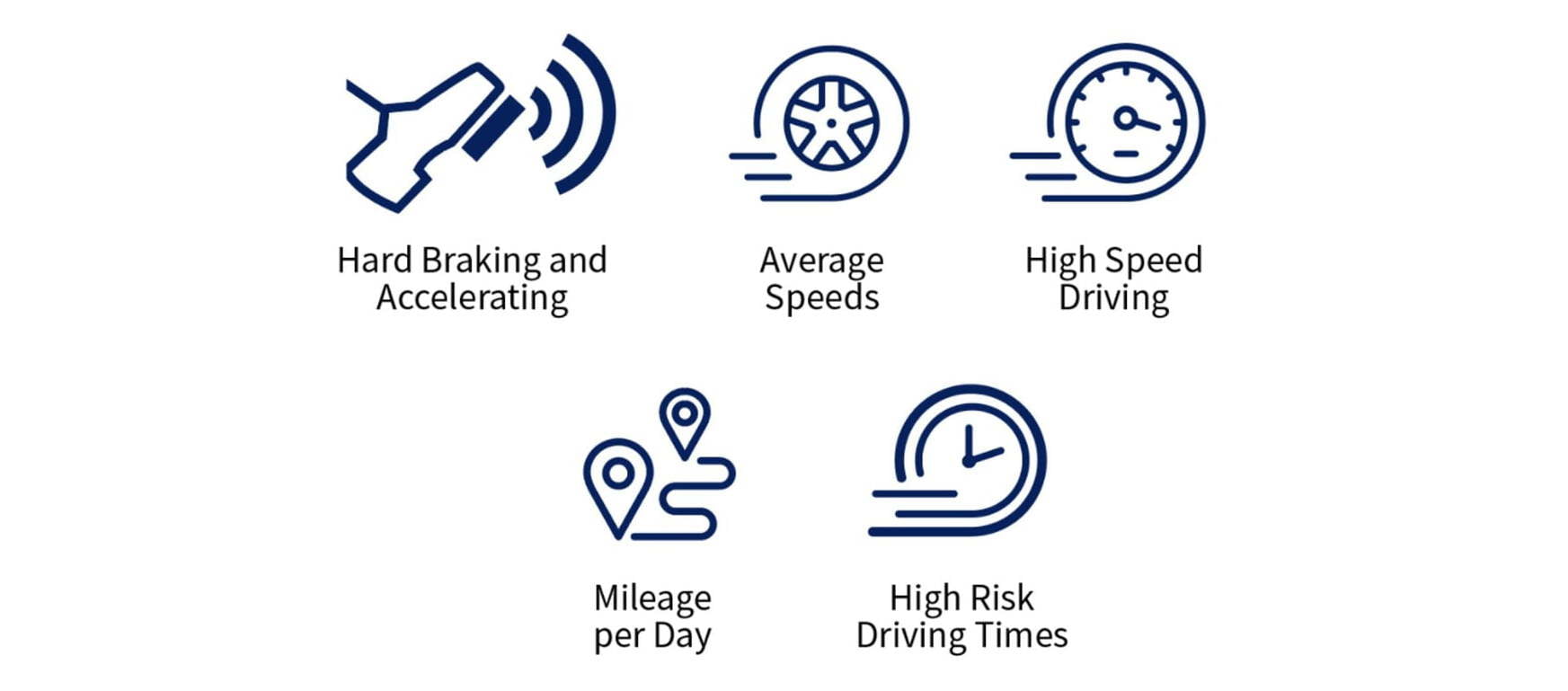
When including an attribute like mileage into a model, more miles should predict a higher likelihood of an accident, and not the other way around. This not only helps to validate the performance of the model but also makes it explainable to someone who is not a data scientist. The attributes in our new model include hard braking and accelerating, average driving speeds, high speeds driving, mileage per day and high-risk driving times. The attributes are conceptually easy to grasp, increase or decrease in risk propensity in a reasonable way, and show consistent performance between development and validation.
Figure 4. LexisNexis telematics data can provide an extremely robust view of driving behavior.
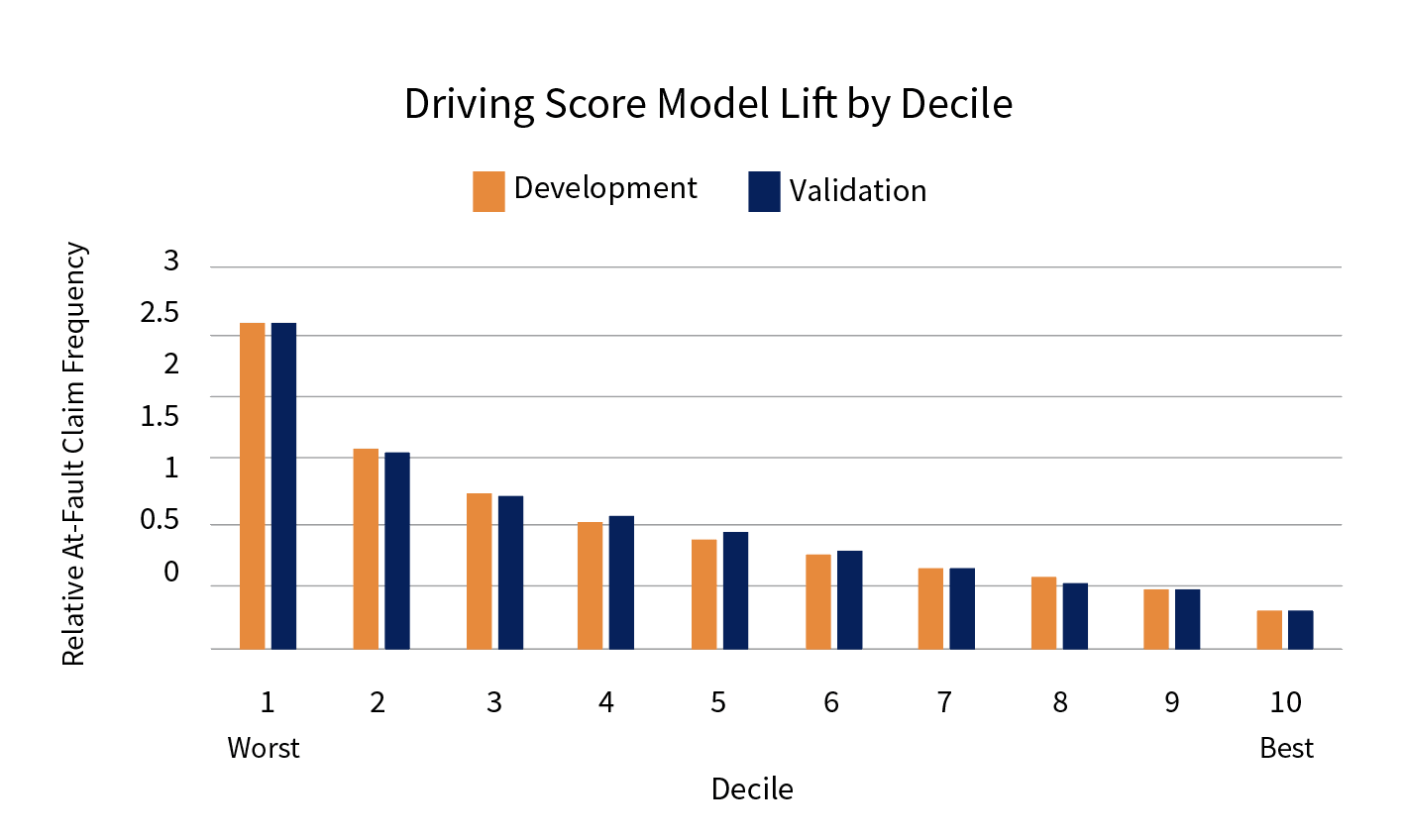
We utilized driving and claims exposure windows throughout the calendar year to avoid issues of seasonality and implemented a 75/25 training/validation split. To put our model to the test, we compared the performance of our development and validation sets. Predictions were rank ordered from worst to best and grouped into ten equal buckets according to the score. In a random model, the trajectory would be flat and the ratio between top and bottom claim frequency would be 1. In this case, the separation power is very high at 8.7x lift. As seen in Figure 5, the development and validation values are nearly identical in performance as you move across deciles―demonstrating that the model is very stable.
When we set out to create a model, we want to maximize both the target lift and the separation between the best and worst buckets of performance, as well as the separation throughout the curve―which we measure utilizing the Gini Index. In our case, these metrics improved hand in hand during the modeling process; if they were to diverge, we would have to keep the use case of the model in mind to determine the optimal metric to prioritize.
Figure 5. LexisNexis telematics scoring model performance, separation and stability align.
If the model or any attribute performs substantially different between development and validation, it could indicate performance is a fluke or possibly exaggerated.
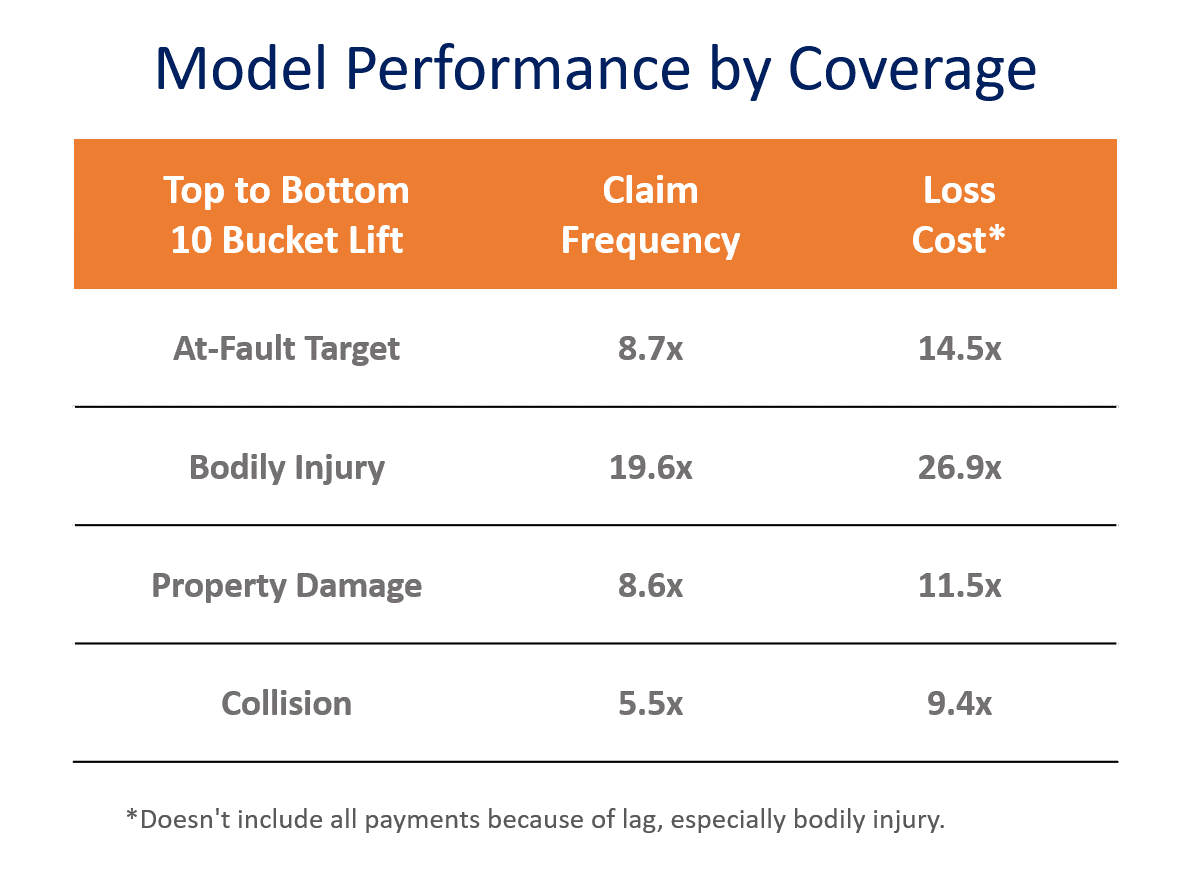
The score should provide you with improved segmentation and lift, so you can better attract and retain customers and, thus, boost profitability. It’s not enough to have access to telematics data. You need to be able to translate the telematics model performance data into rating factors to fit your needs, whether that’s attracting or retaining more price elastic customers (premium shoppers) or simply creating a more accurate rating plan relative to the expected losses. In Figure 6, you can see that our model performs strongly across coverage types. This allows us to offer differentiated claim relativities and recommended discounts. We modeled with claim frequency because the data was relatively recent (loss cost data can take years to develop) and payouts can sometimes be dependent on an insured’s selected coverage levels. While claim frequency was used for the model target rather than loss cost, performance on loss cost is even higher than modeled.
Note the differences in separation across coverages. By creating rating factors separately for each coverage, you can apply the most accurate discounts or surcharges, reflective of risk propensity.
Figure 6. LexisNexis telematics scoring model performs strongly across coverage types.