About
HPCC Systems
HPCC Systems is an open source data lake platform designed to continuously acquire data from many data sources in both structured and unstructured formats. Data lakes are ideal for use with big data applications because they support extremely large, complex, and diverse datasets, and they easily accommodate new data sources such as IoT. They allow IT groups to quickly create new applications that support changing business needs by unlocking the power of complex data for all users within the organization. They also scale more easily and cost-effectively than relational databases and offer the huge storage and compute resources needed for data analytics. As a result, data lakes enable greater responsiveness for users and external customers, reduced costs, and greater scalability.
A typical HPCC Systems implementation begins with just a few data sources and some initial analytical and reporting tools, but the size, complexity, and capability of the HPCC Systems data lake can grow quickly. Once data is added to the data lake, the process of data enrichment begins. Data enrichment is an evolving, iterative process that extracts as much knowledge as possible from data sources. Once that knowledge is extracted, it's available to other data lake users that need it via a process known as data delivery. During data delivery, HPCC Systems ensures that data is transferred to data lake users in a responsive, secure, and reportable manner.
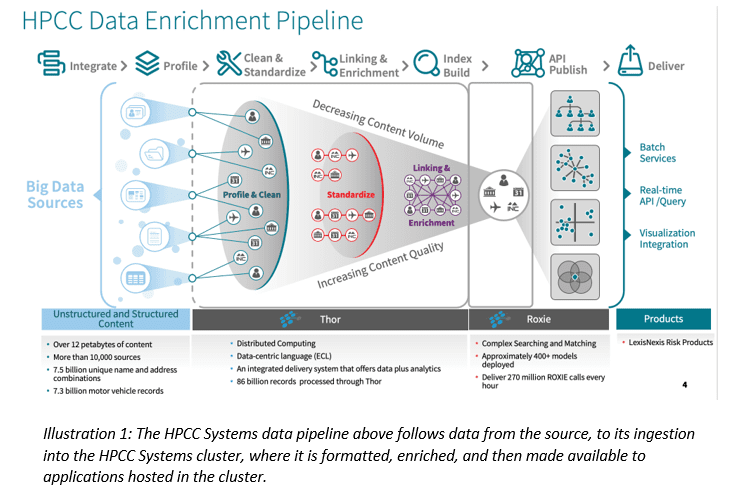
The illustration to the left captures the data lifecycle of an actual HPCC Systems data lake currently in use. Moving left to right, the data sources deliver data to the HPCC Systems data lake for refinement, enrichment, indexing, and analysis. HPCC Systems can generate reports or dashboards about the data at any step in the process, depending on what the report’s consumer needs. All of these processes occur within the data lake environment to produce consistent results.
An HPCC Systems Data Lake is comprised of three primary components:
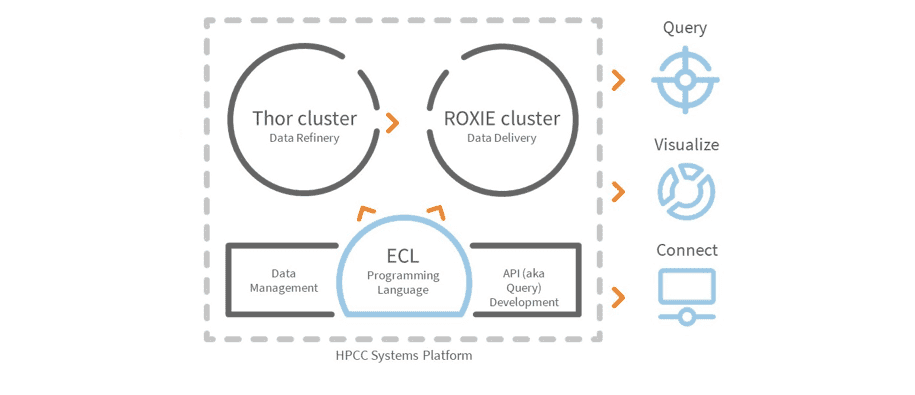
The ECL programming language, which has been in use since 2000, is a data-oriented, declarative programming language developed for use on HPCC Systems data lakes. In layman’s terms, ECL lets developers tell the system what they want, but leaves it up to the system to determine the best way to go about doing it. This results in a smaller, more efficient code base.
Thor is a bulk data processing cluster that cleans, standardizes, and indexes inbound data for use by the data lake. Once data has been refined by Thor it can then be used by the Roxie cluster.
Roxie is a real-time API/Query cluster for querying data after refinement by Thor. Roxie queries execute in sub-second times and provide for very high concurrency.
Illustration 2: An HPCC Systems diagram featuring a Thor cluster (for bulk data processing) and a Roxie cluster (for handling data queries)